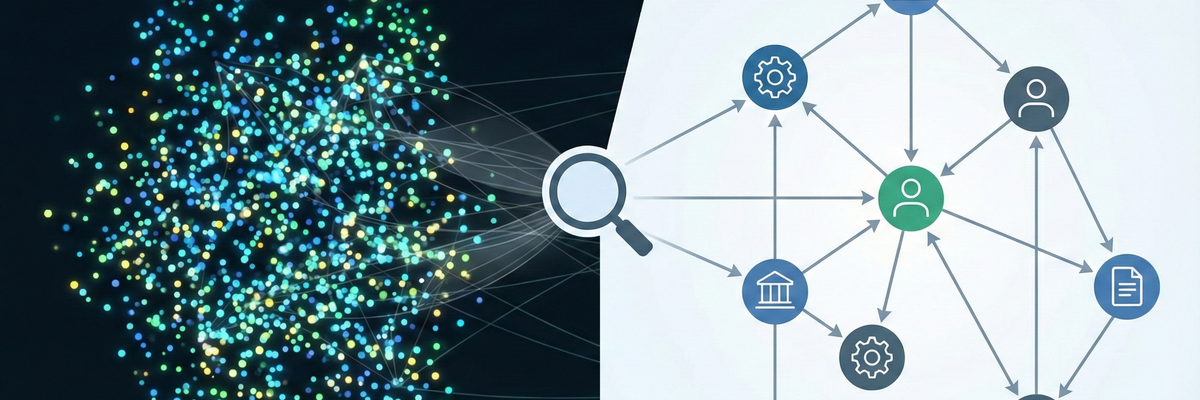
Hier kommt GraphRAG ins Spiel – der nächste logische Evolutionsschritt.
Der Deep Dive: Warum wir Knowledge Graphs (GraphRAG) brauchen.
1. Das Problem: Die "Flachheit" der Vektoren
Stell dir vor, du hast tausende PDF-Dokumente: Verträge, E-Mails, News-Berichte. Du fragst deine KI: "Welches Risiko besteht für unser Projekt 'Alpha' durch die aktuellen Lieferengpässe?"
Standard RAG: Sucht nach Chunks, die die Worte "Risiko", "Projekt Alpha" und "Lieferengpass" enthalten. Es findet vielleicht ein Dokument, das sagt: "Projekt Alpha braucht Stahl."
Das Problem: Die Information, dass der Stahllieferant gerade pleitegegangen ist, steht in einer ganz anderen E-Mail, ohne dass das Wort "Projekt Alpha" dort erwähnt wird. Die Vektorsuche sieht keine semantische Ähnlichkeit und verpasst den Zusammenhang.
2. Die Lösung: Beziehungen statt nur Ähnlichkeit
GraphRAG kombiniert die Unschärfe von Vektoren mit der strikten Logik von Knowledge Graphs.
Anstatt Texte nur als isolierte Punkte im Raum zu speichern, extrahieren wir Entitäten (Personen, Firmen, Orte) und deren Beziehungen (arbeitet für, liefert an, ist Teil von).
3. Die Superkraft: Multi-Hop Reasoning
Das ist der eigentliche Gamechanger. Wenn Dokumente Beziehungen haben, kann die KI "hüpfen" (Hops machen):
- Hop 1 (Dokument A): Projekt Alpha benötigt Komponente X.
- Hop 2 (Dokument B): Komponente X wird hergestellt von Firma Y.
- Hop 3 (Dokument C): Firma Y meldet Insolvenz an.
Eine Vektordatenbank sieht drei isolierte Fakten. Ein Knowledge Graph sieht eine Kette. GraphRAG kann diese Kette ablaufen und dir antworten: "Achtung: Dein Projekt ist gefährdet, weil der Zulieferer deiner Komponente insolvent ist."
Fazit: Die Zukunft ist Hybrid
Vektoren sind unschlagbar für unstrukturierte Ähnlichkeitssuche ("Finde Dokumente über Thema X"). Aber für komplexe Logik, Compliance-Checks und echte Analyse über Silos hinweg brauchen wir GraphRAG. Die besten Systeme der Zukunft werden nicht entweder/oder sein, sondern beides kombinieren.
Frage an das Netzwerk: Habt ihr schon mit Knowledge Graphs (z.B. Neo4j) in Verbindung mit LLMs experimentiert, oder verlasst ihr euch noch rein auf Embeddings?